








Innodata offers industry-leading data solutions to help you build, train, and deploy powerful Traditional and Generative AI models. With a global workforce, Innodata provides high-quality data for:
Fuel your traditional and generative AI/ML models with high-quality annotated training data. Our team of subject matter experts delivers accurate, reliable, and domain-specific data annotation services across all data types in 85+ languages.
Image, Video, & Sensor Annotation: From faces to places, power your visual-based and computer vision models with high-quality annotated data.
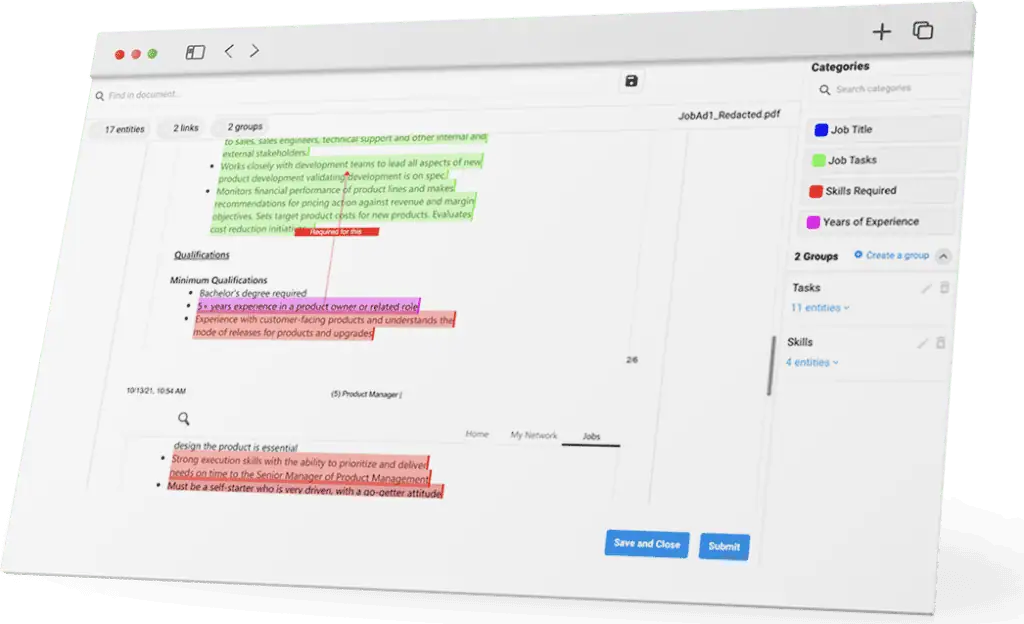
Text Annotation: Train your models with high-quality data annotated from the most complex text, code, and document sources.
Speech & Audio Annotation: Scale your audio-based AI/ML models and ensure model flexibility with diverse speech data in 40+ languages.
of a data scientist’s time is built building training datasets, according to a leading cloud computing enterprise.*
Let Innodata source and collect speech, audio, image, video, text, and document training data for generative and traditional Al model development. We support 85+ languages worldwide and offer customized data collection services to meet any domain requirements.
Whether you need natural data collection, studio data capture, or on-the-ground data gathering, Innodata delivers custom datasets tailored to your unique model training needs.
Additionally, develop LLM prompts with high-quality prompt engineering, allowing in-house experts to design and create prompt data that guide models in generating precise outputs.
of respondents in a recent survey said their organization adopted AI-generated synthetic data because of challenges with real-world data accessibility.*
of respondents in a recent survey said fine-tuning an LLM successfully was too complex, or they didn’t know how to do it on their own.*
Rely on human experts-in-the-loop to close the divide between model capabilities and human preferences. Improve hallucinations and edge-cases with ongoing feedback to achieve optimal model performance through methods like RLHF (Reinforcement Learning from Human Feedback) and DPO (Direct Policy Optimization).
of respondents in a recent survey said RLHF was the technique they were most interested in using for LLM customization.*
reduction in the violation rate of an LLM was seen in a recent study on adversarial prompt benchmarks after 4 rounds of red teaming.*
Fuel your traditional and generative AI/ML models with high-quality annotated training data. Our team of subject matter experts delivers accurate, reliable, and domain-specific data annotation services across all data types in 85+ languages.
Image, Video, & Sensor Annotation: From faces to places, power your visual-based and computer vision models with high-quality annotated data.
Text Annotation: Train your models with high-quality data annotated from the most complex text, code, and document sources.
Speech & Audio Annotation: Scale your audio-based AI/ML models and ensure model flexibility with diverse speech data in 40+ languages.
of a data scientist’s time is built building training datasets, according to a leading cloud computing enterprise.*
Let Innodata source and collect speech, audio, image, video, text, and document training data for generative and traditional Al model development. We support 85+ languages worldwide and offer customized data collection services to meet any domain requirements.
Whether you need natural data collection, studio data capture, or on-the-ground data gathering, Innodata delivers custom datasets tailored to your unique model training needs.
Additionally, develop LLM prompts with high-quality prompt engineering, allowing in-house experts to design and create prompt data that guide models in generating precise outputs.
of respondents in a recent survey said their organization adopted AI-generated synthetic data because of challenges with real-world data accessibility.*
of respondents in a recent survey said fine-tuning an LLM successfully was too complex, or they didn’t know how to do it on their own.*
Rely on human experts-in-the-loop to close the divide between model capabilities and human preferences. Improve hallucinations and edge-cases with ongoing feedback to achieve optimal model performance through methods like RLHF (Reinforcement Learning from Human Feedback) and DPO (Direct Policy Optimization).
of respondents in a recent survey said RLHF was the technique they were most interested in using for LLM customization.*
reduction in the violation rate of an LLM was seen in a recent study on adversarial prompt benchmarks after 4 rounds of red teaming.*



With 5,000+ in-house SMEs covering all major domains from healthcare to finance to legal, Innodata offers expert annotation, collection, fine-tuning, and more.

Fuel Traditional and Generative AI with Innodata.
Data solutions for Traditional and Generative AI model development.
